Cassandra Basics - Primary Keys
Published on 2019-07-08
I recommend reading Cassandra Basics - Introduction before reading this post. It contains setup instructions to run the examples below.
To me, it is more helpful to think of Cassandra as a key value store with more features instead of a tabular database with fewer features. Aside from being less disappointing, it helps remind me how important the primary key of a Cassandra record is. Keys radically constrain the types of queries you can make efficiently and learning to navigate these constraints was probably one of the most frustrating and confusing things I had to learn switching from SQL databases to Cassandra. In this post we will cover how to navigate these constraints in practice. In some later posts I will explain some of the reasons why these constraints are necessary.
To learn about primary keys let’s examine a simple example: a photo storage site. Your photo storage site allows users to store some photos in albums. You want to enable users to get all of the photos from an album with the album ID and you also want a unified view where users can view every photo they’ve uploaded.
We have four fields we want to store for each photo:
user_id: the globally unique ID of the user that owns the photoalbum_id: the globally unique ID of the album the photo is inphoto_id: the globally unique ID of the photophoto_url: the URL of the photo, used to display it
If we try to create a table in Cassandra with these fields we immediately encounter a problem:
CREATE TABLE photos(
user_id int,
album_id int,
photo_id int,
photo_url text
);
Error: No PRIMARY KEY specified (exactly one required)
 So what is a primary key and how do we specify one?
So what is a primary key and how do we specify one?
Primary Keys in Cassandra are a lot like the addresses of houses. In a later post I’ll explain how they are actually similar to physical addresses under the hood as well. Let’s take a look at two small towns: Squaresville and Blockton.
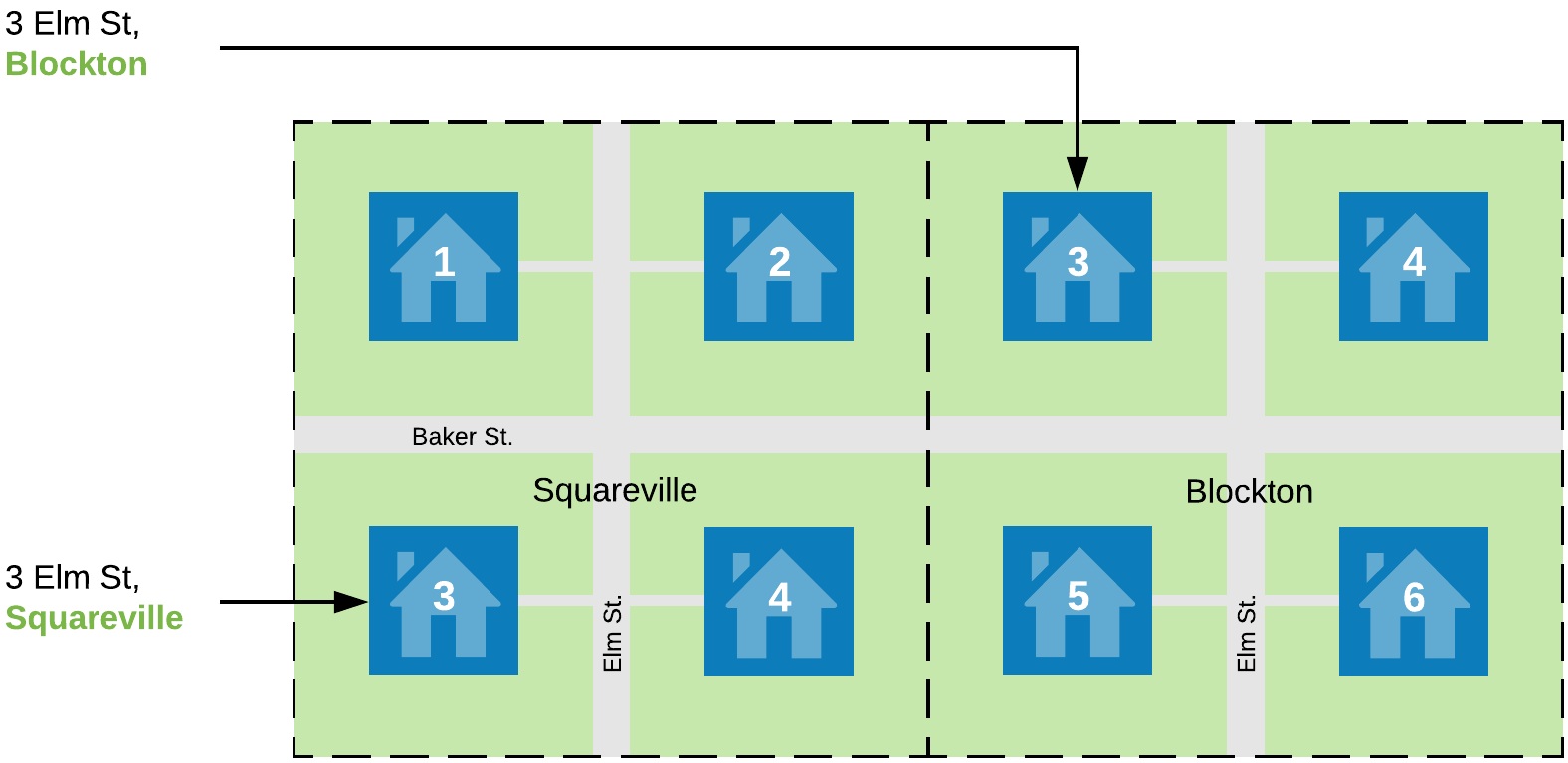
The founders of these towns were pretty unoriginal, so both of them have Elm Streets. In real towns this happens all the time, for example, there are 10,866 Second Streets in the United States (beating out First Street by nearly a thousand oddly enough). Squareseville and Blockton end up having houses with the same street addresses like 3 Elm St, but this is totally fine because they're in different towns.
If you had a map with lots of towns like these and were searching for the address 3 Elm Street, Squaresville it would be much faster to first find Squaresville and then find Squaresville's Elm Street instead of checking every Elm Street, to see if it’s in Squaresville. Every single town could have it's own Elm Street so so knowing the street without the town might not narrow down your search at all. The same pattern continues with street numbers; it would be even worse to check every single house number 3 to see if it is both on Elm Street and in Squaresville.
If the citizens of Squareseville and Blockton put aside their differences and combined their two towns to form Rectopolis it may be great for their citizens but the addresses would have a problem.
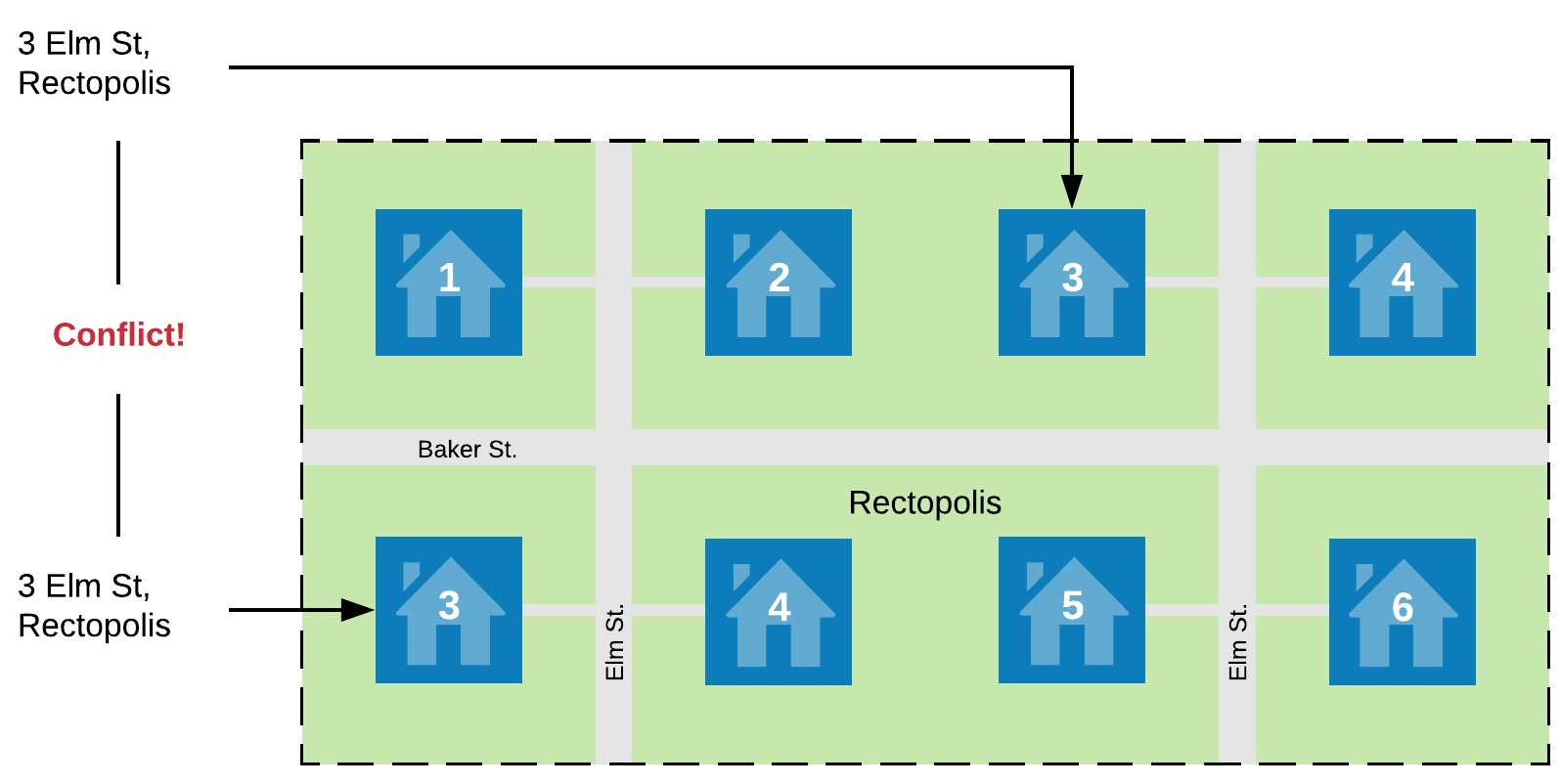
We would like the two 3 Elm Streets to have different addresses but we can’t now that the town has two different Elm Streets. When naming streets in a town it’s not important to make your street names different from every street on earth but it is important to make sure they are unique from all the other street names in the same town. Once again, the same principle applies for street numbers one level down. Having two of the same number on the same street would also leave houses with the exact same address.
So How Does This Apply To Cassandra Primary Keys?
Cassandra needs every record to have a unique primary key just like every house needs to have a unique address. To make a unique primary key let's think about our IDs for a moment. In our app each user, album, and photo has a unique ID. A user can have many albums but an album only belongs to one user. An album can have many photos but a photo only belongs to one album.
Since each row represents a photo, and each photo has a unique ID, every row will have a unique photo ID. The simplest way we could key this table so that every row has a unique primary key would be to use the photo ID. Here is how we would do it:
CREATE TABLE photos(
user_id int,
album_id int,
photo_id int PRIMARY KEY,
photo_url text
);
Now creating the table actually works. If you wanted to make a table to get photo URLs by photo ID then this table would work great. Unfortunately, if we try to get all of the photos for a user we run into an error:
SELECT * FROM photos WHERE user_id=11;
Error: Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING
As a newcomer to Cassandra you may be tempted to use ALLOW FILTERING as the error message suggests but if you take one thing from this post I would hope it is this: if you are using ALLOW FILTERING you are almost certainly doing something wrong. From the perspective of Cassandra this is like searching for a house by checking every single house on earth to see if it has the correct address.
Put another way, that query has similar performance to doing this with code:
from cassandra.cluster import Cluster
from cassandra.auth import PlainTextAuthProvider
auth_provider = PlainTextAuthProvider(
username='cassandra', password='cassandra'
)
cluster = Cluster(auth_provider=auth_provider)
session = cluster.connect('photos')
def user_photos(user_id):
for row in session.execute('SELECT * FROM photos'):
if row.user_id == user_id:
yield row
Cassandra will be a bit faster than python but the performance of the query and the performance of the code above will scale linearly with the size of the entire table. If you do end up needing to do something like this (perhaps in an offline script) I would actually advise you to do this via code instead of using ALLOW FILTERING to make the performance characteristics of your queries more explicit.
So how can we design our primary key to allow us to efficiently get all of the photos for a user? Getting records by a primary key is very fast so let's see what happens if we just use the user ID as our primary key. Here is how we would make that table:
CREATE TABLE photos(
user_id int PRIMARY KEY,
album_id int,
photo_id int,
photo_url text
);
Creating the table works just fine. Let's try adding a photo and see what happens.
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 21, 31, 'url_1');
SELECT * FROM photos WHERE user_id=11;
user_id | album_id | photo_id | photo_url
---------+----------+----------+-----------
11 | 21 | 31 | url_1
Seems good so far, Cassandra no longer complains about getting all of the photos for a user. But what happens when we add another photo to this user?
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 21, 32, 'url_2');
SELECT * FROM photos WHERE user_id=11;
user_id | album_id | photo_id | photo_url
---------+----------+----------+-----------
11 | 21 | 32 | url_2
Our first picture is gone! What happened? Since we are only keying by the user ID every photo belonging to the same user has the same primary key. This would be like abandoning street addresses and only using the town's name; every house in the town would have the exact same address. As humans, we know that these photos have different IDs and URLs making them different but if we don't reflect these differences in the primary key Cassandra doesn't know this.
In Cassandra the INSERTs and UPDATEs are actually upserts. If you INSERT a record and a record with a primary key that already exists it will update that record with the values from the INSERT statement, overwriting what was already there. This is what happened to our missing picture. Conversely, if you UPDATE a record that does not exist, it will be created with the values from the UPDATE statement. In Cassandra the only fields that are mandatory to insert or update a record are those in the primary key so Cassandra will happily create a record with only the primary key and the field you updated if you update a non-existent record. You may end up with records that don't conform to your expected schema because of this behavior if you aren't careful. It is possible get separate insert and update behavior using lightweight transactions, which I will discuss in a later post, but your performance will suffer. Using these should be the exception not the rule. You also can't UPDATE any part of the primary key of a record, you must delete it and recreate it. These properties demonstrate how deeply tied a record is with its primary key and why Cassandra is a really a type of key value store.
Because all inserts are upserts by default, if two records are inserted with the same primary key Cassandra will simply overwrite the one it thinks is older. In Cassandra's town if two houses have the same address, the older one gets bulldozed. When I first learned Cassandra I made this mistake in the application I was working on resulting in libraries that could only ever have one item.
So to prevent our photos from being overwritten we want to put more than one piece of information in our primary key. To do this we will need a primary key statement. This is just a statement at the bottom of our schema that we can use to specify a more complicated primary key. One way we can combine information in our primary key is to make a Composite Partition Key. Here is how to create one with a primary key statement (note the double parentheses, these are required):
CREATE TABLE photos(
user_id int,
album_id int,
photo_id int,
photo_url text,
PRIMARY KEY ((user_id, album_id, photo_id))
);
This key allows us to distinguish between all of our records based on the primary key, so no more bulldozing. But if we try to SELECT from it with just the user_id we get the data filtering error again. With composite partition keys you need every piece of the primary key with every query. Since our photo IDs are globally unique on their own adding these other pieces to the composite partition key just requires more information for every query. Making a composite partition key on this table just takes query options away from us without any advantages compared to keying by just the photo_id so it is clear that this is not the right choice for our table.
The use case for composite partition keys is when your records can guarantee that a combination of their fields will be globally unique but not a single field. The example from the official documentation is annual bicycle races. An annual bicycle race may have the same name every year it is held. This means that a bicycle race with the same name occurs more than once, so the name field is not unique. However, since the race is annual there will only be one per year. This means a combination of the race's name and the year the race was held can be guaranteed to be unique. In this example, you could create a composite partition key by race name and year. Since the table in our photo example has a field that is globally unique for each record it is not a good use case for composite partition keys. In a later post I will discuss the idea of what a partition key is more specifically.
So how can we make a primary key with our fields that will allow us to make multiple types of queries? If we think back to our house addresses we can fit our various IDs to address pieces. Users have many albums like a town has many streets. Albums have many photos like a street has many houses. Our photo IDs are all unique so it's as if we gave every house on earth it's own number. Even though that helps us tell our photos apart we still want to use the other IDs so Cassandra can narrow it's search for all of the photos belonging to a particular user or album. To put this relationship into practice we can use a Compound Primary Key. Here is how we can create our table with a compound primary key with all of our IDs (note the lack of double parenthesis when compared to composite partition keys):
CREATE TABLE photos(
user_id int
album_id int,
photo_id int,
photo_url text,
PRIMARY KEY (user_id, album_id, photo_id)
);
Creating a compound primary key is like giving Cassandra our addressing system. The order of the keys is the order that Cassandra will use the keys to key our records. This key structure means we can query all of the photos owned by a particular user and also guarantee every photo has a unique primary key:
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 21, 31, 'url_1');
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 21, 32, 'url_2');
SELECT * FROM photos WHERE user_id=11;
user_id | album_id | photo_id | photo_url
---------+----------+----------+-----------
11 | 21 | 31 | url_1
11 | 21 | 32 | url_2
We can also get all the photos in one of the user's albums. Let's add a photo to a different album and get all the photos in album 21:
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 22, 33, 'url_3');
SELECT * FROM photos WHERE user_id=11 AND album_id=21;
user_id | album_id | photo_id | photo_url
---------+----------+----------+-----------
11 | 21 | 31 | url_1
11 | 21 | 32 | url_2
This query gives us only the photos in the album. Note how we need to include the user_id as well even if our album_id happens to be globally unique. This is because you need the earlier parts of your compound primary key before you can use later ones. Just like you couldn't find all the houses on a street without knowing the town, Cassandra can't find all of the photos in an album without knowing the user that album belongs to.
Uniqueness
Cassandra enforces uniqueness just like our address system does. It only guarantees that the entire primary key is globally unique, not any individual part. We want our photo IDs to be globally unique but Cassandra has no way of doing this. If we insert two photos (with different URLs) in different albums with the same ID both will get inserted:
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 21, 31, 'url_1');
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(11, 21, 32, 'url_2');
SELECT * FROM photos WHERE user_id=11 AND album_id=21;
user_id | album_id | photo_id | photo_url
---------+----------+----------+-----------
11 | 21 | 31 | url_1
11 | 21 | 31 | url_2
There is also no way that Cassandra can efficiently support a globally incrementing ID. I will explain this more in detail later but here is a short explanation. Cassandra is distributed across several nodes and we want each node to be able to be able to create records. Maintaining a global largest ID counter between them would require coordination between these nodes every time they create a record to ensure that two nodes don't create a record with the same ID before they had time to inform each other. This coordination would be a performance bottleneck.
This is why in practice you should use uuids as your IDs. Luckily Cassandra has a built in uuid a data type and column. Cassandra uses version 4 uuids for these columns. Here is how to create our table with uuid columns:
CREATE TABLE photos(
user_id uuid,
album_id uuid,
photo_id uuid,
photo_url text,
PRIMARY KEY (user_id, album_id, photo_id)
);
And we can insert records using the uuid() function:
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(uuid(), uuid(), uuid(), 'url_1');
SELECT * FROM photos;
This works but there is no way of getting the records you just created so won't have the uuid on hand in the code. This would be fine for something like the photo_id since we always select photos by their albums but if we wanted to create a few records in different tables for our users when they sign up you will want to handle generating your uuids in code so you have access to them. I personally prefer to always generate them in code. Here is an example:
from uuid import uuid4
from cassandra.cluster import Cluster
from cassandra.auth import PlainTextAuthProvider
auth_provider = (
username='cassandra', password='cassandra'
)
cluster = Cluster(auth_provider=auth_provider)
session = cluster.connect('photos')
user_id = uuid4()
album_id = uuid4()
photo_id = uuid4()
photo_url = 'url_1'
insert_query = """
INSERT INTO photos(user_id, album_id, photo_id, photo_url)
VALUES(%s, %s, %s, %s)
"""
session.execute(insert_query, (user_id, album_id, photo_id, photo_url))
Conclusion
In this post we covered the usage of primary keys, composite partition keys, compound primary keys, and uniqueness in Cassandra. Hopefully, you can now see the kinds of constraints that Cassandra primary keys place on your system. Though it may seem somewhat challenging these constraints are crucial to the performance and scalability that Cassandra provides and I will explain more as to why in later posts.